UPDATE customer SET
mobile_no = SUBSTR(mobile_no , 1, 6) || '99999'
WHERE mobile_no <> '';
4.メールアドレス
ドメインはそのままで、アカウント部分を固定値「test」+キー番号とする場合。
UPDATE customer SET
mail = 'test' || CAST(id_customer AS character varying(10)) || '@' || CAST(SPLIT_PART(mail ,'@', 2) AS character varying(64))
WHERE mail <> '';
from django.db import models
from cpkmodel import CPkModel
# Normal Model
# primary_key is auto 'id'
class Company(models.Model):
name = models.CharField(max_length=100)
established_date = models.DateField()
company_code = models.CharField(max_length=100)
class Meta:
db_table = 'Company'
# Child Model (CpkModel)
# composite primary key: company_id, country_code
class CompanyBranch(CPkModel):
company = models.ForeignKey(
Company,
primary_key=True, # for CompositePK
on_delete=models.CASCADE,
)
country_code = models.CharField(
max_length=100,
primary_key=True, # for CompositePK
)
name = models.CharField(max_length=100)
established_date = models.DateField()
class Meta:
managed = False # for CompositePK *1
db_table = 'CompanyBranch'
unique_together = (('company', 'country_code'),) # for CompositePK
1. A number of APIs use “obj._meta.pk” to access the primary key, on the assumption it is a single field (for example, to do “pk=whatever” lookups). A composite PK implementation would need to emulate this in some way to avoid breaking everything.
class CPkQueryMixin():
:
###########################
# override
###########################
:
def add_q(self, q_object):
:
def make_q(keys, vals):
q = Q()
for key, val in zip(keys, vals):
q.children.append((key, val))
return q
assert isinstance(obj, (Q, tuple))
if isinstance(obj, Q):
:
else:
# When obj is tuple,
# obj[0] is lhs(lookup expression)
# pk and multi column with lookup 'in' is nothing to do in this, it will change in 'names_to_path'.
# obj[1] is rhs(values)
# valeus are separated in this method.
names = obj[0].split(LOOKUP_SEP)
if ('pk' in names and self.model.has_compositepk) or CPK_SEP in obj[0]:
# When composite-pk or multi-column
if len(names) == 1:
# change one Q to multi Q
keys = separate_key(self, obj[0]) """! キーを分ける !"""
vals = separate_value(keys, obj[1]) """! 値を分ける !"""
if len(keys) == len(vals):
return make_q(keys, vals) """! make multi conditions !"""
else:
raise ProgrammingError("Parameter unmatch : key={} val={}".format(keys, vals))
else:
# check the last name
last = names[-1]
if last == 'in':
:
elif last == 'pk' or CPK_SEP in last:
# change one Q to multi Q
# example: ('relmodel__id1,id2', (valule1,value2))
# |
# V
# ('relmodel__id1', valule1)
# ('relmodel__id2', valule2)
before_path = LOOKUP_SEP.join(names[0:-1])
cols = separate_key(self, last)
keys = [before_path + LOOKUP_SEP + col for col in cols] """! キーを分ける !"""
vals = separate_value(cols, obj[1]) """! 値を分ける !"""
return make_q(keys, vals) """! make multi conditions !"""
else:
# another lookup is not supported.
raise NotSupportedError("Not supported multi-column with '{}' : {}".format(last,obj[0]))
return obj
new_q = transform_q(q_object)
super().add_q(new_q)
class CPkQueryMixin():
:
###########################
# override
###########################
:
def names_to_path(self, names, opts, allow_many=True, fail_on_missing=False):
meta = self.get_meta()
first_name = names[0]
# name[0] is Multi-Column ?
if (first_name == 'pk' and self.model.has_compositepk) or CPK_SEP in first_name:
# get CompisteKey
ckey = meta.pk
if first_name != 'pk' and first_name != ckey.name:
# IF Not PK, make another CompositeKey
cols = [meta.get_field(col) for col in first_name.split(CPK_SEP)]
ckey = CompositeKey(cols) """! 複数カラムをCompositeKeyでまとめる !"""
lookups = names[1:] if len(names) > 1 else []
return [], ckey, (ckey,), lookups
else:
return super().names_to_path(names, opts, allow_many, fail_on_missing)
1.2 A number of things use (content_type_id, object_pk) tuples
2. A number of things use (content_type_id, object_pk) tuples to refer to some object — look at the comment framework, or the admin log API. Again, a composite PK system would need to somehow not break this.
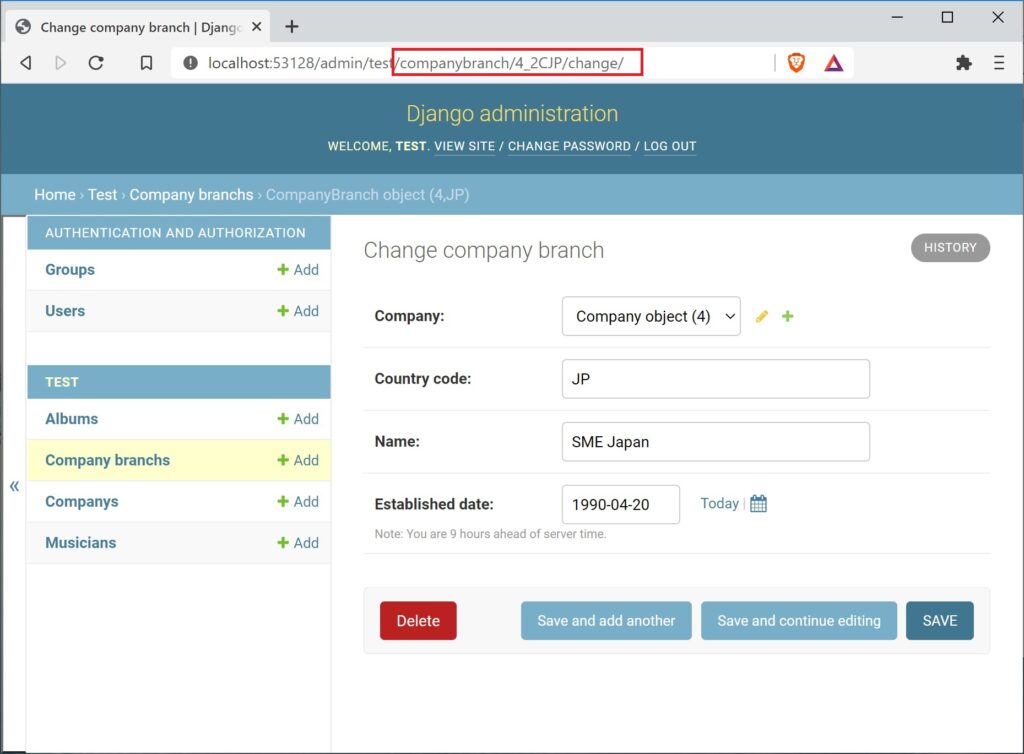
3. Admin URLs; they’re of the form “/app_label/module_name/pk/”; there would need to be a way to map URLs to objects with a set of columns for the primary key.